Database Ownership in Microservices: Beyond the Database-per-Service Rule
By Aakash Ahuja Category: Practical Microservices Field Manual Reading time: 22–28 minutes Published: June 13, 2026
Database ownership in microservices is not mainly about creating one physical database server for every service. It is about deciding which service owns which data, which service is allowed to write that data, and how every other service must access it.
The database-per-service rule is useful, but often misunderstood. The real rule is simpler:
A service should own its domain data and logic. Other services should not directly write to that service's owned tables.
Microsoft's .NET microservices guidance states that each microservice must own its domain data and logic under an autonomous lifecycle with independent deployment (Microsoft Learn). Microservices.io describes the database-per-service pattern as keeping persistent data private to the service and accessible only through its API (microservices.io).
That does not mean every early-stage system must immediately run ten separate database clusters. It does mean the team must stop treating one shared database as the integration layer between services. This is the data half of the boundary problem covered in microservices architecture design — services are only as independent as their data ownership.
Table of contents
- What is database ownership in microservices?
- Why does database ownership matter more than database count?
- Should every microservice have its own database?
- Shared database vs service-owned data: what is the real difference?
- What usually fails when microservices share tables?
- What is the practical migration path from shared database to owned data?
- How should Auth, UMS, and RBAC own their data?
- How should Catalog, Pricing, Availability, Orders, Billing, and Payments own their data?
- How should SCD2 and effective-dated data be owned?
- How does no-FK/application-managed integrity change ownership?
- How should services access data owned by another service?
- How should reporting work when data is service-owned?
- Database ownership checklist for microservices
- Frequently Asked Questions About Database Ownership in Microservices
- Key Takeaways
What is database ownership in microservices?
Database ownership in microservices means one service is accountable for the data model, write path, invariants, migrations, access rules, and audit behavior for a specific business capability.A service owns data when it controls:
| Ownership area | Practical meaning |
|---|---|
| Schema | The service owns table design, indexes, constraints, and migrations. |
| Writes | Only the owning service writes to the owned tables. |
| Invariants | The service enforces business rules for that data. |
| API contract | Other services access data through APIs, events, or approved read models. |
| Audit | The service records important changes and decision points. |
| Lifecycle | The service controls create/update/expire/archive behavior. |
| Migration | The service can evolve its schema without coordinating every unrelated service. |
For example, if Auth owns credential data, UMS should not directly update credential tables. If Pricing owns pricing rules and price resolution, Catalog should not write pricing-rule tables. If Payments owns payment attempts and gateway references, Orders should not directly mark gateway records as paid.
The ownership boundary must be visible in code, API contracts, database permissions, reviews, and operational runbooks.
Why does database ownership matter more than database count?
Database count is an infrastructure detail. Ownership is an architecture decision.A system can have ten databases and still be tightly coupled if every service can read and write every database. A system can also have one physical database instance and still be moving toward real ownership if each service has its own schema or logical database and strict write boundaries.
The important distinction:
| Question | Weak design | Stronger design |
|---|---|---|
| Who writes this table? | Any service that needs it | One owning service |
| How do other services access this data? | Direct SQL | API, event, projection, read model |
| Who changes schema? | Whoever has a requirement | Owning service |
| Who fixes corrupted data? | Whoever finds it | Owning service |
| Who owns audit rules? | Not clear | Owning service |
| Can the owner deploy independently? | No | Yes, within compatibility rules |
That is the practical point. The danger is not only "one database." The real danger is uncontrolled shared write ownership.
Should every microservice have its own database?
The clean target is that every microservice owns its persistent data and exposes it only through its API or events. That is the database-per-service pattern (microservices.io).But the practical answer depends on maturity.
Do not confuse these four models
| Model | What it means | Risk level |
|---|---|---|
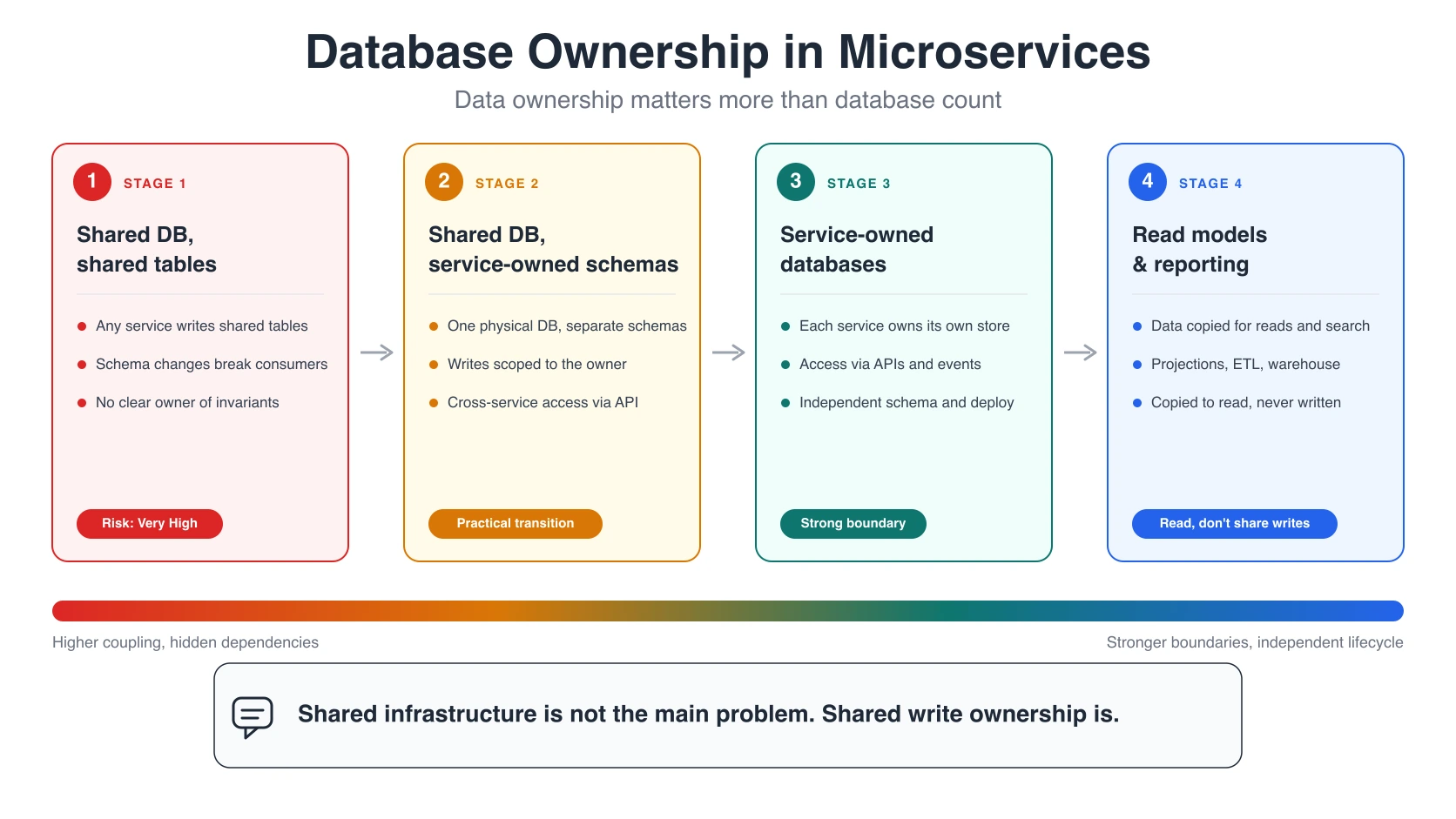
| Shared physical database, shared tables | All services connect to the same DB and write the same tables | Very high |
| Shared physical database, service-owned schemas | Same DB instance, separate schemas/logical DBs per service | Medium |
| Separate physical database per service | Each service has its own DB/server/cluster | Lower coupling, higher ops cost |
| Separate data store type per service | Service chooses SQL, document, key-value, search, etc. | Powerful but operationally heavier |
One physical MySQL/RDS instance, multiple logical databases or schemas, with service-owned tables and API-only cross-service access.
That is often the right interim direction: keep cost and operations manageable, but separate Auth and UMS tables/databases and make them communicate through APIs instead of sharing tables.
This is not architectural purity. It is a practical migration step.
Shared database vs service-owned data: what is the real difference?
A shared database means multiple services treat the same database as a common integration layer. Service-owned data means each service owns its data, and other services must access it through controlled contracts.Shared database pattern
Auth Service ──┐
UMS Service ──┼──> Same user / auth / role tables
RBAC Service ──┘Problem:
- Auth writes user credentials.
- UMS writes user profile and organization membership.
- RBAC writes role assignments.
- Any service can query or update the others' tables.
- Schema changes break multiple services.
- Nobody owns the full invariant.
Service-owned data pattern
Auth Service ── owns ── auth_users / credentials / tokens
UMS Service ── owns ── users / orgs / memberships / profiles
RBAC Service ── owns ── roles / permissions / assignmentsServices communicate through APIs:
UMS asks Auth: create login identity
Business service asks RBAC: is this actor allowed?
Auth validates token; UMS resolves membership; RBAC evaluates permissionAzure's microservice data guidance states that each microservice manages its own data, which makes data integrity and consistency important design challenges (Azure Architecture Center).
That is the tradeoff. You reduce coupling, but you must design consistency deliberately.
What usually fails when microservices share tables?
Shared tables make microservices look independent while keeping them operationally coupled.Failure 1: Schema changes become cross-service deployments
If five services read the same table, one column change can break all five. The team then needs coordinated deployments, compatibility patches, or manual release sequencing.
That removes one of the main reasons to use microservices.
Failure 2: No service owns the business invariant
Example:
- Auth sees a user as active.
- UMS sees the user as inactive in an organization.
- RBAC still has active role assignments.
- Product service allows access because one check passed.
Failure 3: Services bypass API behavior
If a table is directly accessible, developers will eventually query or update it directly "just for now."
That bypasses:
- validation,
- authorization,
- tenant checks,
- audit logging,
- event publishing,
- SCD2 history,
- idempotency,
- cache invalidation.
Failure 4: Reporting becomes the excuse for coupling
Teams often keep shared tables because reporting needs joins.
That is understandable, but dangerous. Reporting needs should be solved with projections, read models, event streams, ETL/ELT, or analytics replicas — not uncontrolled operational writes.
Failure 5: Tests pass but production behavior breaks
A service-level test may pass because the table exists. But production breaks when another service changes semantics, updates a row unexpectedly, or modifies effective dates.
Shared tables create hidden dependencies that are hard to see in tests.
What is the practical migration path from shared database to owned data?
Do not start by splitting every database physically.Start by making ownership explicit.
Database Ownership Maturity Matrix
| Level | State | What it means | Next improvement |
|---|---|---|---|
| Level 0 | Shared DB, shared tables | Any service reads/writes common tables | Assign table owners |
| Level 1 | Shared DB, table ownership documented | Ownership exists on paper | Enforce write ownership in code |
| Level 2 | Shared DB, service-owned schemas | One physical DB, separate service schemas/logical DBs | Block cross-service writes |
| Level 3 | Service-owned DBs | Each service has its own logical/physical database | Add API/events/read models |
| Level 4 | Service-owned data + projections | Operational writes are owned; read models support reporting/search | Add outbox/CQRS where needed |
| Level 5 | Independent lifecycle | Schema, deploy, audit, and contracts evolve independently | Mature operational governance |
Practical migration sequence
- Inventory tables. List every table and identify current readers/writers.
- Assign an owner service. Every table must have one owning service.
- Classify access. Mark access as owner write, owner read, foreign read, foreign write, report read, migration-only, or deprecated.
- Stop new cross-service writes. Existing exceptions can be tracked, but no new service should directly write another service's table.
- Introduce APIs for owned data. Replace direct reads/writes with service contracts.
- Move tables into service schemas/logical DBs. Keep one physical DB if needed, but split ownership.
- Create read models for cross-service views. Do not make operational tables public just because a UI needs a combined view.
- Add audit and correlation IDs. Data changes should be traceable across service calls.
- Physically split later if justified. Separate physical DBs when scaling, security, operations, or lifecycle needs justify the cost.
How should Auth, UMS, and RBAC own their data?
Auth, UMS, and RBAC are related, but they should not casually share ownership.Recommended ownership map
| Service | Owns | Should not own |
|---|---|---|
| Auth | Credentials, login identities, token issuance/validation, auth sessions, password reset/token flows | Organization memberships, business permissions, user profile attributes |
| UMS | User profiles, organizations, memberships, product/module access, user attributes | Passwords, token secrets, permission evaluation logic |
| RBAC | Roles, permissions, assignments, access policies, permission checks | User profile details, credentials, business records |
| Audit/Logging | Auth events, RBAC decisions, business action traces, error logs | Domain truth owned by business services |
Practical example
If a new user is created, UMS may own the business user profile and organization membership. Auth may own login identity and credentials. RBAC may assign default roles.
Bad design:
UMS directly inserts auth credential rows.
RBAC directly updates user profile rows.
Business service directly reads role tables.Better design:
UMS calls Auth API to create login identity.
UMS calls RBAC API to assign initial role.
Business service calls RBAC or receives evaluated permissions through trusted context.The point is not to create three services for the sake of it. The point is to keep identity, membership, and authorization rules separate enough to change safely.
Tenant context rule
In a multi-tenant system, tenant context must be derived from verified authentication/service context, not casually trusted from a request body. This is the same principle that governs API contracts in microservices: the actor and tenant are part of the contract, not optional payload fields.
Database ownership must support that rule:
- every tenant-scoped table needs
tenant_id, - every write path must enforce tenant boundary,
- every API must know the actor and tenant,
- audit records must capture actor, tenant, action, and resource.
How should Catalog, Pricing, Availability, Orders, Billing, and Payments own their data?
A common mistake is making "Product" own everything that appears on a product page.That creates a broad service that knows too much. Azure's microservice-boundary guidance recommends deriving boundaries from the domain model and avoiding hidden dependencies between services (Azure Architecture Center).
Better ownership map
| Service | Owns | Should not own |
|---|---|---|
| Catalog | Offering facts, names, descriptions, categories, bundle structure, stable attributes | Final price, availability, wallet balance, invoices, payment status |
| Pricing | Price rules, tax inputs where applicable, discounts, promotion resolution, pricing snapshots | Catalog descriptions, stock, invoice issuance |
| Availability | Stock, capacity, slots, resource availability | Price computation, payment state |
| Orders | Customer intent, selected items, persisted order state, confirmed order snapshot | Gateway credentials, catalog master data |
| Billing/Invoicing | Invoice records, billing documents, invoice status, credit notes | Payment gateway credential storage |
| Payments | Payment attempts, payment status, gateway references, webhook event processing | Order business lifecycle beyond payment facts |
| Memberships/Quotas/Wallet | Entitlements, consumption, wallet/funding logic | Catalog content, gateway webhooks |
Why Catalog should not own final price
Catalog should return stable offering facts. Pricing should calculate or resolve price. Availability should answer stock/capacity. Orders should persist the customer's selected state. Billing should issue financial documents. Payments should track payment attempts and provider references.
If Catalog returns final price, availability, wallet balance, tax, invoice state, and payment status, Catalog becomes a composition service and loses its clean ownership boundary.
A UI may need one combined response. That does not mean one service should own all the underlying data. Use a composition layer or read model for combined views.
How should SCD2 and effective-dated data be owned?
SCD2-style data tracks changes over time using effective dates, usuallyst_dt and e_dt, so the system can know what value was active at a given time.For example, user profile attributes can be modeled as SCD2-style rows:
userkey
uservalue
data_type
st_dt
e_dtThe design implication is simple:
The service that owns the effective-dated table must own the rule for closing the old row, opening the new row, validating datatype, and deciding what counts as the live value.
Other services should not directly update those rows.
Why this matters
Effective-dated data is easy to corrupt. Common mistakes:
- two active rows for the same key,
- wrong
e_dt, - missing close date,
- datatype changed without validation,
- backdated change applied without audit,
- consumer reads historical value when it expected live value.
Ownership rules for SCD2 data
| Rule | Reason |
|---|---|
| One service owns the SCD2 table | Prevents conflicting update rules |
| One API owns live-value resolution | Prevents each service implementing its own filter |
| Datatype validation belongs to the owner | Prevents invalid historical records |
| Backdated changes require explicit contract | Avoids silent history rewriting |
| Audit old and new values where needed | Supports investigation |
| Consumers should not query SCD2 tables directly | Prevents inconsistent interpretation |
GET /v1/users/{user_id}/attributes/live
PATCH /v1/users/{user_id}/attributesThe PATCH endpoint should own:
- required attribute validation,
- datatype validation,
- no-op detection,
- closing old active row,
- inserting new active row,
- audit event,
- error contract.
How does no-FK/application-managed integrity change ownership?
If a system avoids database-level foreign keys across services, the application must enforce integrity deliberately.No-FK design is not automatically wrong. It can be a practical choice in microservices because cross-service database constraints create coupling. But it raises the standard for API contracts, validation, audit, and operational checks.
What changes when there are no cross-service foreign keys
| Concern | Database FK world | Application-managed integrity world |
|---|---|---|
| Reference validation | DB rejects invalid reference | Owning service/API must validate |
| Delete behavior | DB can restrict/cascade | Business service must define lifecycle |
| Orphan records | DB can prevent | Reconciliation jobs/checks needed |
| Transaction boundary | Single DB transaction possible | Cross-service consistency must be designed |
| Debugging | Constraint failure visible | Need logs, audits, correlation IDs |
| Reporting | Joins are direct | Read models/projections needed |
Practical rule
If you remove database-enforced integrity, replace it with:
- explicit ownership,
- validation APIs,
- idempotent writes,
- audit logs,
- reconciliation jobs,
- status fields,
- correlation IDs,
- error contracts,
- operational dashboards.
How should services access data owned by another service?
A service should access another service's owned data through one of four controlled paths:- API call.
- Event subscription.
- Read model/projection.
- Approved reporting/analytics replica.
Access pattern decision table
| Need | Better access pattern |
|---|---|
| Need current authoritative value | Call owner service API |
| Need to react to a change | Subscribe to event |
| Need a combined UI view | Use API composition or read model |
| Need analytics/reporting | Use reporting replica, warehouse, or ETL/ELT |
| Need high-volume search | Use search projection |
| Need transaction-like business process | Use workflow/Saga/outbox design |
What not to do
Do not let service B query service A's tables because:
- it is faster,
- the API does not exist yet,
- reporting needs it,
- the team is in a hurry,
- "it is only read access."
If direct read access is temporarily unavoidable, document it as debt with:
- owner approval,
- exact table/columns,
- read-only DB credentials,
- expiry date,
- migration plan,
- audit/monitoring.
How should reporting work when data is service-owned?
Reporting is the common reason teams resist database ownership.The concern is valid. Business reporting often needs data from Catalog, Orders, Billing, Payments, Memberships, and Users.
But operational service tables should not become the reporting integration layer.
Better reporting patterns
| Pattern | When to use |
|---|---|
| API composition | Small, real-time operational views |
| Read model | Frequently used combined views |
| Event-driven projection | Data changes need to feed reporting/search |
| ETL/ELT to warehouse | Analytics and business reporting |
| CDC pipeline | When database changes must feed downstream systems |
| Search index | Search-heavy read paths |
Owned data can be copied for reading. It should not be jointly written.
A reporting model can combine data. That does not mean the reporting model owns the source data. For example:
- Catalog owns offering facts.
- Orders owns customer order state.
- Billing owns invoice state.
- Payments owns payment attempts.
- Reporting can join copies/projections of all four.
Database ownership checklist for microservices
Use this checklist before creating or splitting a service.Service data ownership checklist
| Question | Good answer | Risk signal |
|---|---|---|
| Does every table have one owner service? | Yes | Table has multiple writers |
| Can other services write this table? | No | Shared write access |
| Can other services read internal tables? | No, except approved read models | Direct SQL reads everywhere |
| Is tenant ownership enforced? | Tenant comes from verified context | Tenant trusted from payload |
| Is audit required for changes? | Defined per operation | Logging is inconsistent |
| Are schema migrations owner-controlled? | Yes | Any team modifies table |
| Are invariants enforced by owner? | Yes | Rules duplicated across services |
| Are SCD2/effective-dated tables owner-controlled? | Yes | Multiple services update active rows |
| Are no-FK references validated? | Through APIs or reconciliation | Invalid references possible |
| Is reporting separated from operational ownership? | Yes | Reports query operational tables directly |
| Is there a migration path for shared tables? | Yes | "We will clean it later" |
| Are service credentials scoped? | Per service/schema | Shared DB superuser credentials |
| Are secrets stored safely? | Vault/Secrets Manager | Secrets in service tables |
| Are API contracts defined? | Yes | Consumers depend on table shape |
Minimum ownership document
For every owned data area, document:
Owner service:
Owned tables/schemas:
Write APIs:
Read APIs:
Events emitted:
Allowed consumers:
Tenant boundary:
Audit requirements:
SCD2/effective dating rules:
Migration owner:
Backup/retention considerations:
Known exceptions:
Exit plan for exceptions:This document is more useful than a diagram with boxes and arrows.
Frequently Asked Questions About Database Ownership in Microservices
What is database ownership in microservices?
Database ownership in microservices means one service owns the schema, write path, business rules, migrations, and audit behavior for a specific set of data. Other services should access that data through APIs, events, or approved read models instead of directly writing the owner's tables.
Does every microservice need its own database?
The target pattern is that every microservice owns its data, but that does not always require a separate physical database server from day one. A shared physical instance with service-owned schemas or logical databases can be a practical transition step if write ownership is enforced.
Can microservices share one database?
They can share one physical database during early or transitional stages, but they should not freely share tables. The dangerous pattern is multiple services reading and writing the same tables without clear ownership.
What is the database-per-service pattern?
The database-per-service pattern keeps each service's persistent data private and accessible only through that service's API. It helps reduce coupling, but it also requires deliberate handling of consistency, reporting, and cross-service workflows.
What is the difference between shared database and service-owned data?
A shared database is an infrastructure arrangement. Service-owned data is an ownership rule. The same physical database can contain service-owned schemas, but multiple services should not write the same owned tables.
How should services join data from multiple owners?
Operational services should not join directly across other services' tables. Use API composition, read models, projections, events, search indexes, or reporting warehouses depending on the use case.
How do SCD2 tables work with microservices?
The service that owns the effective-dated table should own the logic for closing old rows, opening new rows, validating datatype, resolving live values, and auditing changes. Other services should not directly update SCD2 rows.
What happens if there are no foreign keys across services?
If cross-service foreign keys are avoided, the application must enforce integrity through APIs, validation, audit logs, reconciliation checks, and ownership rules. Without those controls, invalid references and orphan records become likely.
Key Takeaways
- Database ownership in microservices is mainly about data responsibility, not physical database count.
- The database-per-service rule means service-owned data, not blindly creating more database servers.
- Shared physical infrastructure can be acceptable during transition; shared write ownership is the real danger.
- Auth, UMS, and RBAC should own different data even though they work together.
- Catalog should own offering facts, not pricing, availability, orders, invoices, or payment state.
- SCD2/effective-dated tables need one owner service and one interpretation of live vs historical values.
- If foreign keys are removed across services, API validation, audit, reconciliation, and ownership rules become more important.
- Reporting should use read models, projections, or warehouses, not uncontrolled operational table access.
Continue learning: Practical Microservices Field Manual
This article is part of the Practical Microservices Field Manual.Recommended next reads:
- Microservices Architecture Design
- API Contracts in Microservices
- Service-to-Service Authentication in Microservices (coming soon)
- Testing Microservices Without Fooling Yourself (coming soon)
Part of the series
Designing Scalable Microservices- 1.Microservices Architecture Design: Why Services Fail, When to Avoid Them, and How to Draw Boundaries That Survive Production
- 2.API Contracts in Microservices: How to Design Interfaces That Survive Production
- 3.Database Ownership in Microservices: Beyond the Database-per-Service Rule← you are here
- 4.Service-to-Service Authentication in Microservices: A Practical Architecture Guide
- 5.Testing Microservices Without Fooling Yourselfcoming soon
- 6.Observability for Microservices Before Productioncoming soon
