Microservices Architecture Design: Why Services Fail, When to Avoid Them, and How to Draw Boundaries That Survive Production
By Aakash Ahuja Category: Practical Microservices Field Manual Reading time: 18–22 minutes Published: May 23, 2026
Microservices architecture design is not mainly about splitting code into smaller services. It is about splitting ownership, data responsibility, deployment responsibility, failure responsibility, and production accountability.
A system does not become a microservices system because it has multiple repositories, multiple APIs, or multiple deployment units. Those are implementation details. A system becomes a microservices system when each service has a clear business responsibility, owns its data and behavior, exposes stable contracts, and can be changed without constant coordination with every other part of the application.
Martin Fowler’s definition of microservices describes them as small services built around business capabilities, independently deployable, and communicating through lightweight mechanisms. That definition is useful because it puts business capability and independent deployment at the center, not technology fashion. ([martinfowler.com][13])
This article is the first part of the Practical Microservices Field Manual. It focuses on the design decisions that matter before teams start writing services.
In this article:
- What is the practical answer to microservices architecture design?
- Why do microservices fail in real companies?
- When should you not use microservices?
- Microservices vs modular monolith: how should teams choose?
- How do you identify real service boundaries?
- Why should ownership be split before code is split?
- Is database-per-service a rule, a myth, or a practical constraint?
- How do practical constraints change microservice design decisions?
- What readiness checklist should teams use before choosing microservices?
- What is a better first design process for microservices?
- Frequently Asked Questions
Table of contents
- What is the practical answer to microservices architecture design? {#what-is-it}
- Why do microservices fail in real companies? {#why-fail}
- When should you not use microservices? {#when-not}
- Microservices vs modular monolith: how should teams choose? {#vs-monolith}
- How do you identify real service boundaries? {#boundaries}
- Why should ownership be split before code is split? {#ownership}
- Is database-per-service a rule, a myth, or a practical constraint? {#database}
- How do practical constraints change microservice design decisions? {#constraints}
- What readiness checklist should teams use before choosing microservices? {#readiness-checklist}
- What is a better first design process for microservices? {#design-process}
- Frequently Asked Questions About Microservices Architecture Design {#faq}
- Key Takeaways {#key-takeaways}
- References
What is the practical answer to microservices architecture design? {#what-is-it}
Microservices architecture design is the process of deciding which business capabilities should become independently owned services, what data each service owns, how services communicate, how they are deployed, and how failures are observed and contained.The practical answer is simple:
Do not start by asking, “How many services should we create?”
Start by asking, “What responsibilities must be independently owned, changed, deployed, secured, audited, and operated?”
That one shift prevents many bad designs.
A useful microservice has these properties:
| Property | Practical meaning |
|---|---|
| Clear business responsibility | The service owns one meaningful business capability, not a random technical layer. |
| Data ownership | The service owns the data required for its responsibility. Other services do not casually write to its tables. |
| Stable contract | Other services interact through APIs, events, or approved integration mechanisms. |
| Deployment independence | The service can be changed and released without releasing the whole system. |
| Operational ownership | A team or owner is responsible for alerts, incidents, logs, cost, and documentation. |
| Failure isolation | Failure should be contained where possible and should not automatically bring down unrelated workflows. |
AWS describes microservices as an architectural and organizational approach where small independent teams own services and communicate through well-defined APIs. That organizational part is not optional. ([Amazon Web Services, Inc.][14])
Why do microservices fail in real companies? {#why-fail}
Microservices fail when teams split software before they split responsibility.The common failure pattern looks like this:
- A team has a growing monolith.
- The monolith becomes hard to change.
- Management or engineering decides to “move to microservices.”
- Developers split code into multiple services.
- The same database remains shared.
- The same team owns everything.
- Services call each other synchronously for most workflows.
- Testing becomes harder.
- Debugging becomes slower.
- Deployment coordination becomes worse than before.
A distributed monolith is a system that has multiple services but still behaves like one tightly coupled application. It has the complexity of distributed systems without the independence that microservices are supposed to provide.
Common reasons microservices fail
| Failure mode | What it looks like in practice | Design correction |
|---|---|---|
| Splitting by technical layer | User API, User Logic, User DB, Report API, Report Logic | Split by business capability, not by controller/service/repository layers. |
| Shared database tables | Multiple services read and write the same tables | Assign table ownership and expose data through APIs/events/read models. |
| No service owner | Everyone changes everything | Assign ownership for code, API, data, deployment, alerts, and incidents. |
| Weak API contracts | Breaking changes appear without downstream coordination | Version APIs and define compatibility rules. |
| Synchronous chains | One request depends on five services responding correctly | Use async workflows, caching, read models, or orchestration where appropriate. |
| No observability | Teams cannot trace a failed request across services | Add correlation IDs, structured logs, metrics, and traces before scale. |
| Shared deployment | All services are released together | Question whether services are actually independent. |
| No rollback plan | One service deployment breaks a flow and rollback is unclear | Design deployment and data migration separately. |
The important point: most failed microservices are not caused by REST, Docker, Kubernetes, or cloud choice. They are caused by bad boundaries and weak operating discipline.
When should you not use microservices? {#when-not}
You should not use microservices when the domain is unclear, the team is small, the product is still changing every week, or the organization cannot operate multiple independently deployed services.A modular monolith is often the better first architecture.
A modular monolith is a single deployable application with strong internal module boundaries. It can enforce separation between domains without adding network calls, distributed transactions, multi-service deployments, and cross-service debugging.
Do not start with microservices if these are true
| Condition | Why it matters |
|---|---|
| The product domain is still unstable | You will draw wrong service boundaries and then pay migration cost. |
| The team is small | Service ownership becomes fake because the same people own everything. |
| You cannot observe production well | Distributed systems without observability become hard to debug. |
| You deploy manually | Multiple services multiply release risk. |
| Your database model changes daily | Database-per-service decisions will likely be wrong. |
| You have no clear domain ownership | Teams will split code, not responsibility. |
| You need fast feature discovery | A modular monolith is usually faster until the domain stabilizes. |
| You cannot test integration paths | You will ship broken cross-service workflows. |
The question is not whether microservices are modern. The question is whether your team can operate the architecture it chooses.
Microservices vs modular monolith: how should teams choose? {#vs-monolith}
The choice between microservices and a modular monolith should be based on operational readiness, not architecture preference.| Decision area | Modular monolith | Microservices |
|---|---|---|
| Deployment | One deployable unit | Multiple independently deployable services |
| Team structure | One team or tightly coordinated teams | Multiple teams with clear service ownership |
| Data model | Shared database possible with module boundaries | Service-owned data preferred |
| Failure model | In-process failure paths | Network, timeout, retry, partial failure |
| Debugging | Easier local tracing | Requires distributed tracing/log correlation |
| Speed early in product life | Usually faster | Often slower unless boundaries are stable |
| Long-term scale | Can become hard if modules are weak | Can scale better if ownership is real |
| Operational cost | Lower | Higher |
| Best fit | Unclear or evolving domain | Stable domains with independent ownership |
A weak monolith has random coupling. A strong modular monolith has explicit boundaries, clear module ownership, internal contracts, and discipline around data access.
A weak microservices system has multiple deployables but still shares data, ownership, and release coordination.
The real comparison is not monolith vs microservices. It is:
disciplined boundaries vs accidental coupling.
How do you identify real service boundaries? {#boundaries}
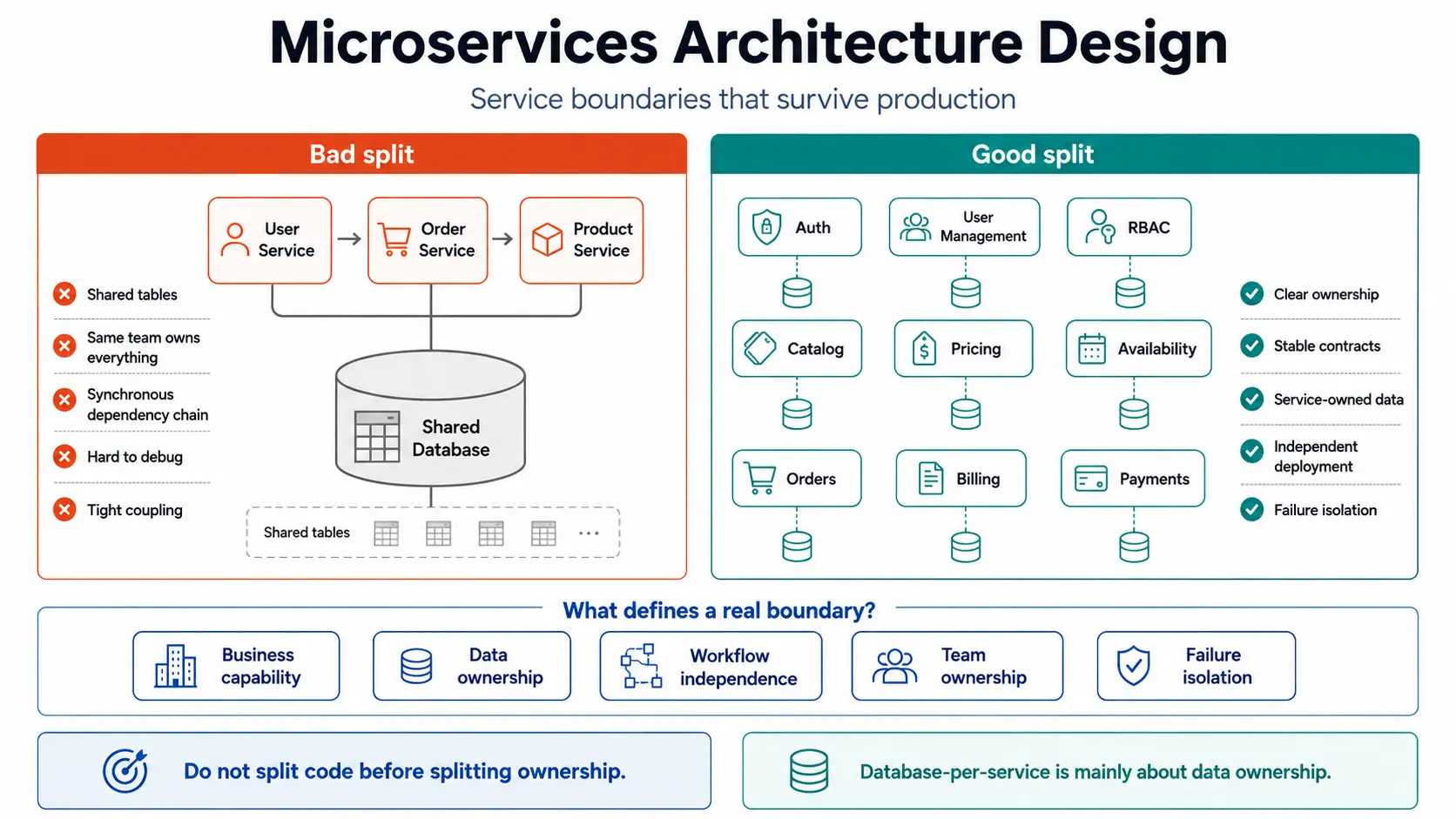
Real service boundaries usually follow business capabilities, data ownership, workflow independence, and team accountability.A service boundary is weak if it is based only on code size, database table names, or nouns in the domain.
For example, “UserService” is not automatically a good microservice. In many systems, “user” is not one business capability. Authentication, profile management, organization membership, permissions, billing identity, employee records, and customer records may all use user-related data but have different responsibilities.
In one practical design path, separating Auth, User Management, and RBAC is not about creating more services. It is about separating responsibilities:
| Service | Responsibility |
|---|---|
| Auth service | Credentials, login, tokens, authentication events |
| User Management service | Users, organizations, memberships, profiles, product access |
| RBAC service | Roles, permissions, assignments, authorization rules |
| Logging/Audit service | Access logs, error logs, audit records, traceability |
If User Management directly writes credential tables, Auth is not the real owner of authentication data. If Product directly computes final pricing, discount, tax, availability, and payment state, Product becomes too broad. If Catalog returns final price and availability, Catalog is no longer a stable catalog service; it becomes a composition layer.
Microsoft’s microservice-boundary guidance recommends starting from bounded contexts and avoiding services that mix different domain models. ([Microsoft Learn][16]) Martin Fowler describes bounded context as a central Domain-Driven Design pattern for dividing large models and being explicit about their relationships. ([martinfowler.com][17])
Practical boundary questions
Ask these before creating a service:
- What business capability does this service own?
- What data does it own?
- What data should it never directly modify?
- Which team or owner handles production incidents?
- Can it be deployed without redeploying unrelated services?
- Does it expose a stable contract?
- Can downstream systems use its output without knowing its internal schema?
- What happens if it is unavailable?
- Does it need synchronous communication, or can it publish events?
- Is the boundary based on real ownership or just code organization?
Why should ownership be split before code is split? {#ownership}
Ownership must be split before code because microservices move complexity from code structure into operating structure.When one team owns all services, all databases, all deployments, and all incidents, the system may still be physically distributed but operationally centralized.
That can be acceptable during a transition, but it should not be mistaken for mature microservices.
What a service owner must own
| Ownership area | What it means |
|---|---|
| Code | The owner approves changes and keeps implementation coherent. |
| API contract | The owner manages compatibility, versioning, and deprecation. |
| Data | The owner controls schema, writes, migrations, and access rules. |
| Deployment | The owner can release and roll back safely. |
| Observability | The owner maintains logs, metrics, traces, dashboards, and alerts. |
| Incidents | The owner responds when the service fails. |
| Security | The owner handles access rules, secrets, and service-level risks. |
| Documentation | The owner maintains operational and integration documentation. |
| Cost | The owner understands infrastructure and usage cost. |
This becomes visible during incidents. If pricing is wrong, who owns the correction? Catalog? Pricing? Promotion? Tax? Order? Billing? If the answer requires a meeting every time, the service model is not clear enough.
A practical pattern is to keep stable facts and computation responsibilities separate.
Example:
| Capability | Better service responsibility |
|---|---|
| Catalog | Canonical offering facts: name, description, category, attributes, media, bundle structure |
| Pricing | Price computation, tax logic, promotion resolution, price run correlation |
| Availability | Stock, capacity, slots, resource availability |
| Order | Customer intent, confirmed line items, persisted pricing snapshot |
| Billing/Invoicing | Invoice generation, billing documents, tax invoice records |
| Payments | Payment attempts, payment status, gateway references |
| Memberships/Quotas | Entitlements, consumption, wallet/funding logic |
Is database-per-service a rule, a myth, or a practical constraint? {#database}
Database-per-service is best understood as a data ownership rule, not as a blind requirement that every service must immediately have a separate physical database server.The core principle is this:
A service should own its domain data and expose that data through controlled contracts.
Microsoft’s .NET microservices guide states that each microservice must own its domain data and logic, and that data should be private to that service’s implementation. ([Microsoft Learn][18]) Microservices.io describes the database-per-service pattern as keeping persistent data private to the service and accessible only through its API. ([microservices.io][19])
In practice, teams often move through stages.
Stage 1: Shared physical database, shared tables
This is common in early systems.
Problem: multiple services read and write the same tables. This creates tight coupling. Schema changes become risky. Ownership is unclear.
This is usually not real microservices.
Stage 2: Shared physical database, separate schemas or databases
This is a practical transition pattern.
One RDS/MySQL/PostgreSQL instance may host multiple logical databases or schemas. Each service owns its own schema/database. Services should not directly modify another service’s schema.
This can be acceptable when cost, operations, and team size do not justify separate physical database infrastructure yet.
Stage 3: Separate physical data stores per service
This is closer to the ideal.
Each service can choose the right store and scale independently. But it increases backup, monitoring, migration, access-control, and operational complexity.
Stage 4: Service-owned data plus read models/events
At higher maturity, other services do not query owned tables directly. They consume APIs, events, projections, or read models.
This is often needed for reporting, search, customer-facing views, and workflow composition.
Practical rule
Do not confuse physical separation with ownership.
A separate database with bad ownership is still bad architecture. A shared physical database with strict schema ownership can be a reasonable transitional design.
The real mistake is allowing multiple services to treat one database as a public integration layer.
Microsoft’s Azure guidance says data storage should be private to the service that owns the data, and APIs should model the domain rather than leak implementation details. ([Microsoft Learn][20])
How do practical constraints change microservice design decisions? {#constraints}
Good microservices design is not made from textbook rules. It is made from constraints.Here are practical constraints that should change design decisions.
Constraint 1: Existing HTTPS may be enough for the first stage
If services already communicate over HTTPS with valid certificates, adding mTLS, VPN, or service mesh may not be the immediate priority.
The better first question is:
- Are tokens validated correctly?
- Are issuer and audience checked?
- Is service-to-service authorization enforced?
- Is tenant context trusted or derived safely?
- Are logs sufficient to investigate cross-service failures?
Constraint 2: JWT content affects service boundaries
If JWTs contain auth_user_id and tenant_id, services must be clear about what those claims mean.
A service should not blindly trust tenant context from arbitrary input. Tenant identity should come from verified authentication context or a trusted service boundary.
In a multi-tenant system, almost every service must answer:
- Which tenant owns this request?
- Which user or service is acting?
- What product/module is being accessed?
- What permission is required?
- What audit record should be written?
Constraint 3: Pure compute endpoints should not write state
A pricing system provides a useful example.
A pure endpoint such as /pricing/resolve can compute price, tax, promotion, and discount results without writing to the database. That makes it easier to test and reuse.
A different endpoint such as POST /orders/{id}:price can compute and persist a pricing snapshot for an order.
This separation matters because calculation and commitment are different responsibilities.
| Endpoint type | Responsibility |
|---|---|
| Pure compute endpoint | Resolve result from inputs; no durable state change |
| Commit endpoint | Persist approved result or business snapshot |
| Query endpoint | Return existing state |
| Admin endpoint | Change configuration or rule set |
Constraint 4: Catalog should not become the customer-facing composition layer
Catalog should own canonical offering facts.
It should not own:
- final customer price,
- tax result,
- stock availability,
- booking slot availability,
- wallet balance,
- payment status,
- membership consumption.
A customer-facing page may need all of them together. That does not mean Catalog should return all of them. A composition layer or view API can assemble the response from Catalog, Pricing, Availability, Memberships, and other services.
This keeps Catalog stable.
Constraint 5: Some central services are necessary
A logging/audit/error service may be centralized because audit and error records cut across all services.
That does not violate microservice design if it is used as an infrastructure capability and does not start owning business logic from other services.
The same applies to notification, file management, identity, and workflow infrastructure.
The design question is:
Is this service a shared infrastructure capability, or is it absorbing unrelated business responsibilities?
Constraint 6: Service boundaries may evolve
A first version does not need perfect separation. It needs explicit separation.
If a system starts with a shared physical database, the ownership rules should still be documented. If a service boundary is provisional, mark it. If one service is temporarily reading another service’s table, treat it as technical debt with an exit path.
Undefined coupling is more dangerous than temporary coupling. Applying sound engineering review discipline to service boundaries — documenting provisional decisions and tracking technical debt explicitly — prevents undefined coupling from accumulating silently.
What readiness checklist should teams use before choosing microservices? {#readiness-checklist}
Use this checklist before approving a microservices architecture.Microservices Architecture Readiness Matrix
| Question | Ready | Risky |
|---|---|---|
| Do we know the main business capabilities? | Capabilities are named and owned | Boundaries are based on tables or controllers |
| Do services have owners? | Each service has code, API, data, and incident owner | Same team owns everything without clear accountability |
| Is data ownership defined? | Tables/schemas have owners | Multiple services write same tables |
| Can services deploy independently? | Independent release and rollback possible | Services must be released together |
| Are API contracts stable? | Versioning and compatibility rules exist | Downstream breakage is common |
| Is observability ready? | Correlation IDs, logs, metrics, traces exist | Debugging requires guessing |
| Are retries and timeouts controlled? | Backoff, timeout, and retry limits exist | Clients retry aggressively or indefinitely |
| Is tenant context enforced? | Tenant comes from verified context | Tenant passed casually in request payloads |
| Are audit requirements clear? | User/action/resource/context/time are logged | Logs are incomplete or inconsistent |
| Can the team test cross-service workflows? | Integration and contract tests exist | Manual testing is the main safety net |
| Can the team operate incidents? | Owners, dashboards, rollback paths exist | Production support is improvised |
These concerns matter more in microservices because every network call introduces another possible timeout, retry, overload, and partial failure path.
What is a better first design process for microservices? {#design-process}
A practical microservices design process should follow this order:- Map the business capabilities.
- Identify ownership boundaries.
- Identify data ownership.
- Separate stable facts from computed or customer-specific views.
- Decide which operations are pure computation and which persist state.
- Define API contracts.
- Define tenant, auth, and authorization context.
- Define logging and audit requirements.
- Define failure behavior.
- Decide deployment boundaries.
- Only then create repositories, services, and databases.
Infrastructure is important, but it should support the service model. It should not define the service model.
A service exists because the business responsibility needs independent ownership, not because a diagram needs another box.
Frequently Asked Questions About Microservices Architecture Design {#faq}
What is microservices architecture design?
Microservices architecture design is the process of dividing a system into independently owned services with clear business responsibilities, data ownership, APIs, deployment boundaries, and operational accountability. It is not just splitting code into multiple repositories or containers.
Why do microservices fail?
Microservices fail when teams split code without splitting ownership, data, deployment responsibility, and observability. The common result is a distributed monolith: many services that remain tightly coupled through shared databases, synchronous calls, and unclear ownership.
When should a team avoid microservices?
A team should avoid microservices when the domain is unstable, the team is small, deployment is manual, observability is weak, or service ownership is unclear. In those cases, a modular monolith is usually safer and faster.
Is a modular monolith better than microservices?
A modular monolith is better when the product is still evolving and the team needs strong internal boundaries without distributed-system complexity. Microservices are better when boundaries are stable, teams are independent, and services need separate deployment and operational ownership.
Does every microservice need its own database?
Every microservice should own its domain data, but that does not always require a separate physical database server on day one. A shared physical database with strict schema ownership can be a transition step, but multiple services writing the same tables creates tight coupling.
How should teams identify service boundaries?
Teams should identify service boundaries by business capability, data ownership, workflow independence, change frequency, and team accountability. Boundaries based only on table names, controllers, or code size are usually weak.
What is the biggest mistake in microservices architecture design?
The biggest mistake is splitting code before splitting ownership. If the same team owns every service, every database, every deployment, and every incident without clear accountability, the system has not gained the main benefit of microservices.
What should be designed before building microservices?
Teams should design service ownership, data ownership, API contracts, tenant context, authorization rules, audit logs, deployment independence, failure behavior, and observability before building services. Without these, the architecture will likely become harder to operate than the monolith it replaced.
Key Takeaways {#key-takeaways}
- Microservices are an operating model, not just a code structure.
- Service boundaries should follow business capability, data ownership, and operational accountability.
- A modular monolith is often the correct first architecture when the domain is still changing.
- Database-per-service is mainly about data ownership, not blindly creating separate physical databases.
- Shared tables across services are a strong signal of weak boundaries.
- Catalog, Pricing, Availability, Orders, Billing, Payments, and Memberships should not be collapsed into one “Product” service if their responsibilities differ.
- Pure computation endpoints and state-changing endpoints should be separated.
- Tenant context, authorization, logging, and audit must be designed early in multi-tenant systems.
This article is the first in the Practical Microservices Field Manual series. The next article covers API Contracts That Survive Production — how to design interfaces that define behavior, idempotency, errors, tenant context, and versioning, not just schema. Future posts go deeper into database ownership, service-to-service authentication, testing, and observability.
Need to assess whether your system is ready for microservices? Use the Microservices Architecture Readiness Matrix above before creating another service. If you want a structured review of your current service model, get in touch.
References
Microservices are commonly defined as services built around business capabilities and independently deployable through lightweight communication mechanisms. ([martinfowler.com][13])AWS describes microservices as an architectural and organizational approach involving small, independent teams and well-defined APIs. ([Amazon Web Services, Inc.][14])
Microsoft’s Azure Architecture Center recommends deriving microservices from bounded contexts and warns against hidden dependencies and poorly designed interfaces. ([Microsoft Learn][16])
Martin Fowler describes bounded context as a central Domain-Driven Design pattern for dividing large models and making relationships explicit. ([martinfowler.com][17])
Microsoft’s .NET microservices guidance states that each microservice should own its domain data and logic. ([Microsoft Learn][18])
Microservices.io describes database-per-service as keeping persistent data private to the service and exposing it through APIs. ([microservices.io][19])
AWS Builders Library covers timeouts, retries, backoff, and jitter for distributed systems. ([Amazon Web Services, Inc.][21])
Google SRE material explains cascading failures and why overload can spread across systems. ([Google SRE][22])
[13]: https://martinfowler.com/articles/microservices.html?utm_source=chatgpt.com "Microservices" [14]: https://aws.amazon.com/microservices/?utm_source=chatgpt.com "What are Microservices?" [15]: https://learn.microsoft.com/en-us/azure/architecture/microservices/model/domain-analysis?utm_source=chatgpt.com "Use Domain Analysis to Model Microservices" [16]: https://learn.microsoft.com/en-us/azure/architecture/microservices/model/microservice-boundaries?utm_source=chatgpt.com "Identify microservice boundaries - Azure Architecture Center" [17]: https://www.martinfowler.com/bliki/BoundedContext.html?utm_source=chatgpt.com "Bounded Context" [18]: https://learn.microsoft.com/en-us/dotnet/architecture/microservices/architect-microservice-container-applications/data-sovereignty-per-microservice?utm_source=chatgpt.com "Data sovereignty per microservice - .NET" [19]: https://microservices.io/patterns/data/database-per-service.html?utm_source=chatgpt.com "Pattern: Database per service" [20]: https://learn.microsoft.com/en-us/azure/architecture/guide/architecture-styles/microservices?utm_source=chatgpt.com "Microservices Architecture Style - Azure Architecture Center" [21]: https://aws.amazon.com/builders-library/timeouts-retries-and-backoff-with-jitter/?utm_source=chatgpt.com "Timeouts, retries and backoff with jitter" [22]: https://sre.google/sre-book/addressing-cascading-failures/?utm_source=chatgpt.com "Cascading Failures: Reducing System Outage"
Part of the series
Designing Scalable Microservices- 1.Microservices Architecture Design: Why Services Fail, When to Avoid Them, and How to Draw Boundaries That Survive Production← you are here
- 2.API Contracts in Microservices: How to Design Interfaces That Survive Production
- 3.Database Ownership in Microservices: Beyond the Database-per-Service Rule
- 4.Service-to-Service Authentication in Microservices: A Practical Architecture Guide
- 5.Testing Microservices Without Fooling Yourselfcoming soon
- 6.Observability for Microservices Before Productioncoming soon
