API Contracts in Microservices: How to Design Interfaces That Survive Production
By Aakash Ahuja Category: Practical Microservices Field Manual Reading time: 22–28 minutes Published: May 30, 2026
API contracts in microservices fail when teams treat APIs as URLs and JSON payloads instead of operational agreements between services. A production API contract must define behavior, ownership, permissions, errors, retries, versioning, tenant context, auditability, and failure semantics.
An endpoint tells another service where to call. A contract tells that service what it can safely depend on.
That difference decides whether microservices can change independently or whether every release becomes a cross-service coordination problem.
Table of contents
- What is an API contract in microservices?
- Why do microservice API contracts fail in production?
- What should every microservice API contract define?
- API contract vs endpoint: why naming is not enough
- Resource APIs vs action APIs: when should you use each?
- Pure compute endpoints vs state-changing endpoints
- How should tenant, auth, and RBAC context appear in API contracts?
- How should APIs handle idempotency, retries, and duplicate requests?
- What should a production-grade error contract include?
- How should API versioning work in microservices?
- What changes are backward compatible and what changes are breaking?
- How should APIs support audit, tracing, and debugging?
- How should webhook contracts differ from normal API contracts?
- Microservice API contract checklist: questions to ask before approving any endpoint
- Frequently Asked Questions About API Contracts in Microservices
- Key Takeaways
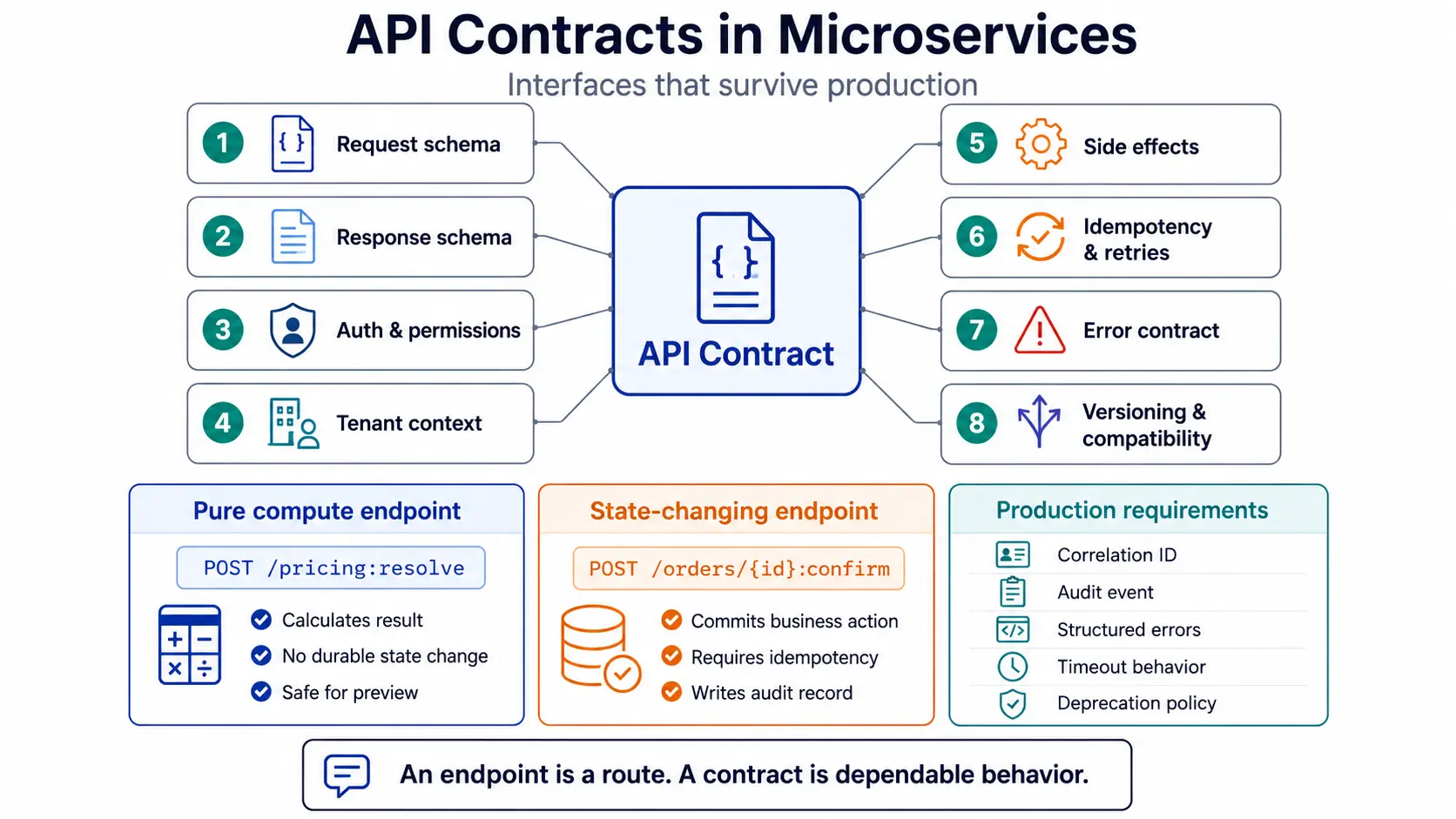
What is an API contract in microservices?
An API contract in microservices is the explicit agreement between a service provider and its consumers about request structure, response structure, behavior, errors, permissions, side effects, versioning, and operational guarantees.A contract includes more than schema.
It answers:
- What does this endpoint do?
- What does it not do?
- Who can call it?
- Which tenant does the request belong to?
- Is the operation read-only or state-changing?
- Can it be retried safely?
- What happens if the same request is sent twice?
- What errors can the caller expect?
- What audit record is created?
- What fields are stable?
- What changes are breaking?
- What correlation ID flows through the call?
Why do microservice API contracts fail in production?
Microservice API contracts usually fail because behavior is not specified with the same seriousness as fields.Common failure pattern:
- Service A exposes an endpoint.
- Service B starts using it.
- Service A changes response fields, validation, side effects, or error behavior.
- Service B breaks.
- Nobody knows whether Service A broke the contract or Service B assumed too much.
- Teams add meetings, hotfixes, flags, and temporary patches.
- Service independence disappears.
Common API contract failures
| Failure | Production symptom | Better contract decision |
|---|---|---|
| Fields added without clarity | Consumers start depending on fields not meant for them | Mark fields as stable, experimental, internal, or deprecated |
| Hidden side effects | A "preview" endpoint changes state | Separate pure compute from commit actions |
| Weak errors | Callers cannot distinguish validation, permission, tenant, and conflict errors | Use structured error contracts |
| Unsafe retries | Duplicate requests create duplicate orders, invoices, or payments | Require idempotency keys for state-changing calls |
| Tenant passed casually | Caller sends tenant_id in body and service trusts it | Derive tenant from verified auth context |
| No correlation ID | Cross-service debugging becomes guesswork | Propagate trace/correlation identifiers |
| Versioning absent | Any change risks downstream breakage | Define compatibility rules and version policy |
| Webhook semantics unclear | External retries cause duplicate processing | Verify signature, deduplicate, and define 200/4xx behavior |
In this article:
- What should every microservice API contract define?
- API contract vs endpoint: why naming is not enough
- Resource APIs vs action APIs: when should you use each?
- Pure compute endpoints vs state-changing endpoints
- How should tenant, auth, and RBAC context appear in API contracts?
- How should APIs handle idempotency, retries, and duplicate requests?
- What should a production-grade error contract include?
- How should API versioning work in microservices?
- What changes are backward compatible and what changes are breaking?
- How should APIs support audit, tracing, and debugging?
- How should webhook contracts differ from normal API contracts?
- API contract checklist for microservices
- Frequently Asked Questions About API Contracts in Microservices
- Key Takeaways
What should every microservice API contract define?
A microservice API contract should define structure, behavior, side effects, security context, error behavior, retry behavior, observability, and compatibility rules.Minimum contract fields:
| Contract area | What to define |
|---|---|
| Resource or action | What business capability this API exposes |
| Request schema | Required fields, optional fields, data types, validation rules |
| Response schema | Stable fields, nullable fields, computed fields, status fields |
| Side effects | Whether the endpoint reads, computes, writes, confirms, cancels, emits events, or creates audit records |
| Auth context | Required user token, service token, scopes, roles, permissions |
| Tenant context | How tenant is derived and enforced |
| Idempotency | Whether duplicate requests are safe and how dedupe works |
| Errors | Error codes, HTTP status, machine-readable details |
| Versioning | Compatibility rules and deprecation path |
| Audit | What action is logged and which identifiers are captured |
| Tracing | Correlation ID or trace context propagation |
| SLA expectation | Expected response behavior, timeout guidance, async fallback where needed |
Do not fight these semantics casually. If a GET endpoint changes state, consumers and infrastructure will make wrong assumptions.
API contract vs endpoint: why naming is not enough
An endpoint is the visible route. A contract is the dependable behavior.Example:
POST /v1/orders/{order_id}:confirmThis endpoint name suggests an action. But the contract must define:
- who can confirm,
- what order states are eligible,
- whether confirmation is idempotent,
- what happens if the order is already confirmed,
- whether pricing is recalculated or uses a stored snapshot,
- whether wallet/entitlement consumption happens,
- whether invoice creation happens,
- what audit events are written,
- what errors can occur.
In a well-designed order flow, actions are separated:
:price:funding-preview:confirm:cancel
/orders/{id}:price should not be treated the same as /orders/{id}:confirm.
A pricing endpoint may calculate and persist a pricing snapshot. A confirmation endpoint may consume wallet balance, apply entitlements, create invoice obligations, or move the order into a committed state. Those are different contracts.
If the API name does not force that distinction, the system becomes unsafe under retries, UI refreshes, partial failures, and downstream integrations.
Resource APIs vs action APIs: when should you use each?
Resource APIs expose entities. Action APIs expose business operations.Both are valid. The mistake is using one style for everything.
Google's API design guidance describes resource-oriented design as a pattern based on resources and standard methods. (Google AIP-121) That is a strong default for CRUD-like operations. But production systems also need explicit business actions.
Resource API examples
GET /v1/users/{user_id}
PATCH /v1/users/{user_id}/attributes
GET /v1/orders/{order_id}
POST /v1/ordersUse resource APIs when the operation is naturally about creating, reading, updating, or deleting a resource.
Action API examples
POST /v1/orders/{order_id}:price
POST /v1/orders/{order_id}:confirm
POST /v1/invoices/{invoice_id}:issue
POST /v1/credit-notes/{credit_note_id}:apply
POST /v1/offline-payments/{payment_id}:mark-receivedUse action APIs when the operation represents a business transition, not a generic update.
Decision rule
| Question | Better API style |
|---|---|
| Are you changing fields on a resource? | Resource API |
| Are you moving a business object through a lifecycle? | Action API |
| Does the operation require permissions, validations, audit, and side effects? | Action API |
| Is the operation a pure read? | Resource API |
| Is the operation a domain command? | Action API |
PATCH.Bad:
PATCH /v1/orders/{id}
{
"status": "confirmed"
}Better:
POST /v1/orders/{id}:confirm
{
"idempotency_key": "..."
}The second contract makes the business transition explicit.
Pure compute endpoints vs state-changing endpoints
A pure compute endpoint returns a calculated result without changing durable state. A state-changing endpoint commits a business action.This distinction is important for pricing, eligibility, availability, tax, funding, and preview flows.
Pure compute endpoint
Example:
POST /v1/pricing:resolveExpected behavior:
- accepts input,
- calculates result,
- returns result,
- does not persist order state,
- does not consume entitlement,
- does not issue invoice,
- does not change wallet,
- may log request metadata for diagnostics.
State-changing endpoint
Example:
POST /v1/orders/{order_id}:priceExpected behavior:
- calculates price for the order,
- persists pricing snapshot,
- records pricing version/rule references,
- prepares the order for confirmation,
- writes audit record.
Committed business action
Example:
POST /v1/orders/{order_id}:confirmExpected behavior may include:
- validates order state,
- checks tenant and actor permissions,
- verifies pricing snapshot,
- consumes wallet or entitlement where applicable,
- creates invoice obligation if applicable,
- changes order status,
- writes audit record,
- returns final committed state.
Why this matters
If /pricing:resolve has hidden writes, consumers cannot use it safely for UI previews. If /orders/{id}:confirm silently recalculates price, the user may confirm a different amount than the one previewed. If /funding-preview consumes wallet balance, a refresh can create financial defects.
Contract rule:
Preview, price, confirm, cancel, issue, apply, and mark-received are different operations. They need different API contracts.
How should tenant, auth, and RBAC context appear in API contracts?
Tenant, authentication, and authorization context should be part of the API contract, but they should not be blindly accepted from request payloads.In multi-tenant microservices, tenant context is not just another field. It defines the data boundary.
Practical rule
A service should derive tenant and actor context from verified authentication context, not from untrusted body fields.
Bad:
{
"tenant_id": "tenant_123",
"user_id": "user_456",
"action": "confirm_order"
}Better:
Authorization: Bearer <user_token>
X-Service-Token: <service_token>
X-Correlation-Id: <correlation_id>Then the service derives:
{
"tenant_id": "from_verified_context",
"actor_user_id": "from_verified_context",
"calling_service": "from_verified_service_token"
}Service responsibility split
| Service | Contract responsibility |
|---|---|
| Auth | Verify identity, issue/validate tokens, authenticate users/services |
| UMS | Manage users, organizations, memberships, profiles, product access |
| RBAC | Evaluate roles, permissions, assignments |
| Product/order services | Enforce tenant-scoped business operations |
| Logging/audit | Record request, error, and action evidence |
Contract fields for secure service calls
| Contract element | Required decision |
|---|---|
| User token | Is a user identity required? |
| Service token | Is the caller another trusted service? |
| Actor | Is the action done by a human, service, or system job? |
| Tenant | How is tenant derived and enforced? |
| Permission | What RBAC permission is required? |
| Product/module gate | Is this feature enabled for the tenant? |
| Audit | What action is logged? |
| Correlation ID | How is the call traced? |
product_ms_enabled=false should return a 403-style denial before deeper business processing. That is not a UI concern. It is part of the API contract.How should APIs handle idempotency, retries, and duplicate requests?
Every state-changing microservice API should define retry and duplicate-request behavior.Retries are normal in distributed systems. Networks fail, clients timeout, workers restart, queues redeliver, users double-click buttons, and external providers resend webhooks.
If the API contract does not define idempotency, duplicate side effects become likely.
Stripe's API documentation describes idempotency keys as unique keys generated by the client so the server can recognize retries of the same request and return the original result for subsequent requests with the same key. (Stripe Docs)
Where idempotency matters
| Endpoint type | Idempotency needed? | Reason |
|---|---|---|
| Create order | Yes | Prevent duplicate orders |
| Confirm order | Yes | Prevent duplicate confirmation/consumption |
| Issue invoice | Yes | Prevent duplicate invoices |
| Apply credit note | Yes | Prevent duplicate application |
| Mark offline payment received | Yes | Prevent duplicate payment status changes |
| Resolve pricing preview | Usually no durable idempotency | Pure compute should have no durable side effect |
| GET resource | HTTP-level idempotent | Read-only |
| Webhook handler | Yes | Providers may retry events |
Recommended idempotency contract
For state-changing calls:
Idempotency-Key: <client-generated-unique-key>Store:
| Field | Purpose |
|---|---|
tenant_id | Idempotency must be tenant-scoped |
actor_id | Optional but useful for security/debugging |
endpoint | Same key should not apply across unrelated operations |
request_hash | Detect same key used with different payload |
status | pending/succeeded/failed |
response_body | Return same response for retry where appropriate |
created_at | Retention cleanup |
correlation_id | Debugging |
Contract behavior
| Situation | Response |
|---|---|
| First request with key | Process and store result |
| Retry with same key and same payload | Return same result |
| Same key with different payload | Return conflict |
| Request already completed | Return final result |
| Request still processing | Return pending/accepted or conflict based on contract |
What should a production-grade error contract include?
A production API error contract should be machine-readable, stable, and specific enough for callers to handle.RFC 9457 defines "problem details" as a standard way to carry machine-readable error details in HTTP API responses. (rfc-editor.org)
You do not need to copy the standard blindly, but the principle is correct: errors need structure.
Poor error response
{
"error": "Something went wrong"
}This is not useful.
Better error response
{
"type": "https://aakashx.com/problems/order-invalid-state",
"title": "Order cannot be confirmed",
"status": 409,
"detail": "Order must be priced before confirmation.",
"code": "ORDER_409_PRICE_REQUIRED",
"correlation_id": "corr_abc123",
"field_errors": []
}Error categories every service should define
| Category | HTTP status | Example code |
|---|---|---|
| Invalid payload | 400 | ORDER_400_INVALID_PAYLOAD |
| Missing required field | 400 | UMS_400_REQUIRED_ATTR_MISSING |
| Invalid datatype | 400 | UMS_400_INVALID_DATATYPE |
| Unauthorized | 401 | AUTH_401_TOKEN_INVALID |
| Forbidden | 403 | RBAC_403_PERMISSION_DENIED |
| Not found | 404 | ORDER_404_NOT_FOUND |
| Conflict | 409 | ORDER_409_INVALID_STATE |
| Idempotency conflict | 409 | ORDER_409_IDEMPOTENCY_CONFLICT |
| Validation conflict | 422 | ORDER_422_BUSINESS_RULE_FAILED |
| Rate limit | 429 | COMMON_429_RATE_LIMITED |
| Internal error | 500 | COMMON_500_INTERNAL_ERROR |
How should API versioning work in microservices?
API versioning should protect consumers from breaking changes while allowing service owners to evolve implementation.Versioning is not only a URL decision. It is a compatibility policy.
Common approaches:
/v1/orders
/v2/ordersor:
Accept: application/vnd.company.orders.v1+jsonFor most internal business microservices, path versioning is easier to understand and operate.
Practical versioning rules
| Rule | Why it matters |
|---|---|
Keep /v1 stable once consumers use it | Prevents silent breakage |
| Add optional fields instead of changing required fields | Preserves compatibility |
| Do not change meaning of existing fields | Breaks consumer assumptions |
| Do not remove fields without deprecation | Breaks clients |
| Do not change enum values silently | Breaks validation logic |
| Use new version for major behavior changes | Makes migration explicit |
| Document deprecation timelines | Lets consumers plan |
| Track consumers before removing old versions | Prevents production surprise |
What changes are backward compatible and what changes are breaking?
API compatibility must be defined before services move independently.Usually backward compatible
| Change | Condition |
|---|---|
| Add optional response field | Existing consumers ignore unknown fields |
| Add optional request field | Old clients still work |
| Add new endpoint | Existing endpoints unchanged |
| Add new enum value | Only if consumers tolerate unknown values |
| Add pagination metadata | Existing response shape remains usable |
| Add correlation ID | Does not change behavior |
| Add new error detail field | Existing error code/status unchanged |
Usually breaking
| Change | Why it breaks |
|---|---|
| Remove response field | Consumer may depend on it |
| Rename field | Equivalent to remove + add |
| Change field type | Breaks parsing |
| Change field meaning | Breaks business logic |
| Make optional field required | Old clients fail |
| Change error code/status | Client handling breaks |
| Change sort order without contract | UI/reporting may change |
| Change default page size significantly | Client behavior may change |
| Add hidden side effect | Retry and preview safety break |
| Change tenant derivation behavior | Security boundary changes |
Dangerous but often missed
Some changes look harmless but are not.
Example:
{
"status": "ACTIVE"
}If consumers treat ACTIVE as "can be billed," changing it to mean "active but pending billing approval" is a breaking semantic change even though the schema did not change.
Contracts protect meaning, not only shape.
How should APIs support audit, tracing, and debugging?
Every production microservice API should support correlation, audit, and error logging.W3C Trace Context defines standard HTTP headers and value formats for propagating context information to enable distributed tracing. (W3C)
Minimum request context
Authorization: Bearer <user_token>
X-Service-Token: <service_token>
X-Correlation-Id: <correlation_id>
traceparent: <w3c_trace_context>Minimum audit fields for state-changing APIs
| Field | Purpose |
|---|---|
tenant_id | Tenant boundary |
actor_user_id | Who initiated |
calling_service | Which service called |
action | Business action |
resource_type | Type of affected object |
resource_id | Object affected |
before_state | Optional, where appropriate |
after_state | Optional, where appropriate |
permission_checked | RBAC evidence |
correlation_id | Cross-service trace |
status | Success/fail/no-op |
error_code | Failure diagnosis |
timestamp_utc | Consistent time basis |
How should webhook contracts differ from normal API contracts?
Webhook contracts are different because the caller is usually an external provider, not your frontend or internal service.A webhook handler should define:
- how signature verification works,
- whether raw body bytes are required,
- what response means success,
- how duplicate events are handled,
- how tenant/provider instance is resolved,
- what happens when event processing fails,
- whether processing is synchronous or queued,
- what audit record is written.
The critical ordering rule
Bad webhook flow:
- Parse JSON.
- Read tenant ID from body.
- Query tenant payment settings.
- Then verify signature.
- Read raw body bytes.
- Identify provider route/instance safely.
- Verify signature.
- Only then process event.
- Deduplicate event.
- Record audit/payment event.
- Return provider-compatible response.
Webhook contract checklist
| Contract area | Required decision |
|---|---|
| Signature verification | Which header, algorithm, raw body requirement |
| Duplicate events | Event ID or provider event key |
| Response semantics | When to return 200, 4xx, or retryable failure |
| Processing model | Synchronous vs queue |
| Tenant resolution | How provider instance maps to tenant |
| Secrets | Never returned in API responses |
| Audit | Store provider event ID, result, and correlation |
| Idempotency | Same event must not apply twice |
Microservice API contract checklist: questions to ask before approving any endpoint
Use this before approving a new microservice endpoint.Microservice API Contract Review Matrix
| Question | Good contract | Weak contract |
|---|---|---|
| Is the endpoint purpose clear? | Resource or action is explicit | Generic update hides business transition |
| Are side effects defined? | Read, compute, write, confirm, cancel, issue are separate | Preview endpoint writes durable state |
| Is tenant context safe? | Derived from verified context | Trusted from request body |
| Is auth/RBAC defined? | Permission required is explicit | "Authenticated user" is assumed enough |
| Is idempotency defined? | State-changing calls handle retries | Duplicate calls create duplicate effects |
| Are errors structured? | Stable codes and status mapping | Free-text error messages |
| Is versioning defined? | Compatibility rules exist | Any field can change anytime |
| Are audit fields defined? | Actor/action/resource/result captured | Logs are incomplete |
| Is trace context propagated? | Correlation ID / trace context flows | Debugging requires manual guessing |
| Is pagination defined? | Limit, cursor/page, sort, defaults specified | Lists can grow unbounded |
| Are timestamps clear? | UTC for system time; tenant-local only where business-specific | Mixed timezone assumptions |
| Are no-op outcomes defined? | Repeated action returns stable result | No-op treated as error randomly |
| Are async cases defined? | 202/status endpoint or workflow ID | Endpoint blocks unpredictably |
| Is ownership clear? | Service owner owns contract and changes | Consumers rely on informal behavior |
Contract template
For each endpoint, document:
Endpoint:
Business purpose:
Owner service:
Consumer services:
Authentication:
Authorization:
Tenant source:
Request schema:
Response schema:
Side effects:
Idempotency:
Error codes:
Audit events:
Trace/correlation:
Timeout expectation:
Version:
Backward compatibility rules:
Deprecation policy:
Examples:Do not approve production APIs without this minimum contract.
Frequently Asked Questions About API Contracts in Microservices
What is an API contract in microservices?
An API contract is the agreement between a service and its consumers about request format, response format, behavior, errors, permissions, side effects, versioning, and operational guarantees. It is broader than endpoint naming or JSON schema.
Why do API contracts matter in microservices?
API contracts matter because microservices depend on each other across network boundaries. Without stable contracts, one service change can break another service, causing release coordination, production incidents, and loss of independent deployment.
Is OpenAPI enough for API contracts?
OpenAPI is useful for describing API structure and generating documentation or clients. It is not enough by itself because production contracts also include behavior, side effects, idempotency, permissions, audit, versioning, and failure semantics.
Should microservices use REST or RPC-style action endpoints?
Use REST-style resource endpoints for normal create/read/update/delete operations. Use action endpoints when the operation represents a business transition such as confirm, cancel, issue, apply, approve, or mark received.
How should APIs handle retries?
State-changing APIs should define idempotency behavior. A client should be able to retry safely using an idempotency key or equivalent deduplication mechanism, especially for orders, payments, invoices, confirmations, and webhook events.
What is a breaking API change?
A breaking change is any change that can break an existing consumer's parsing, validation, workflow, permission handling, or business assumptions. It includes removing fields, changing field meanings, changing error codes, adding required fields, or adding hidden side effects.
Should tenant ID be passed in the API request body?
In multi-tenant systems, tenant ID should usually be derived from verified authentication or service context, not trusted from the request body. Passing tenant ID casually in payloads can create tenant-boundary and authorization problems.
How should microservices design error responses?
Microservices should use structured error responses with stable machine-readable codes, HTTP status, human-readable title/detail, field-level validation errors where needed, and correlation IDs for debugging.
Key Takeaways
- An API contract is an operational agreement, not just a route and JSON schema.
- Microservice APIs must define behavior, side effects, errors, retries, tenant context, audit, and versioning.
- Resource endpoints and action endpoints solve different problems.
- Pure compute endpoints should not hide durable writes.
- State-changing APIs need idempotency rules.
- Tenant context should come from verified auth/service context, not casual body fields.
- Structured error contracts make consumers more reliable.
- Webhooks need different contracts because external providers retry, sign, and resend events.
- API contracts become more important when integrity is application-managed rather than enforced through cross-service foreign keys.
Continue learning: Practical Microservices Field Manual
This article is part of the Practical Microservices Field Manual.Recommended next reads:
- Microservices Architecture Design
- Database Ownership in Microservices
- Service-to-Service Authentication in Microservices (coming soon)
- Testing Microservices Without Fooling Yourself (coming soon)
Part of the series
Designing Scalable Microservices- 1.Microservices Architecture Design: Why Services Fail, When to Avoid Them, and How to Draw Boundaries That Survive Production
- 2.API Contracts in Microservices: How to Design Interfaces That Survive Production← you are here
- 3.Database Ownership in Microservices: Beyond the Database-per-Service Rule
- 4.Service-to-Service Authentication in Microservices: A Practical Architecture Guide
- 5.Testing Microservices Without Fooling Yourselfcoming soon
- 6.Observability for Microservices Before Productioncoming soon
